L7 Ingest
What is it?
The L7 Ingest app is used to bulk import Entities and their metadata from data files. Ingests are defined in the Templates tab and executed in the Ingests tab. These ingests support the creation of parent-child relationships.
Key Terms
Term | Definition |
Ingest Template | Defines how to parse and map data based on the column attribute rules applied to the format of the uploaded file to register new Entities, assign metadata and create parent-child relationships. |
Ingest | An instance, or occurrence, of using an Ingest Template to bulk import Entities from a given file |
Pre-processor | A pluggable extension point allowing you to adapt any file format into a form accepted by the Ingest app before processing |
Post-processor | A pluggable extension point allowing you to perform an action after an Ingest is complete |
From the L7 Ingest tab you can see an overview of all active Ingests, including details about the associated template, file, tags, ingest status, owner, and last activity. Using the different view tabs, Ingests can be organized by Template, Project, File Type, Owner, and List view.
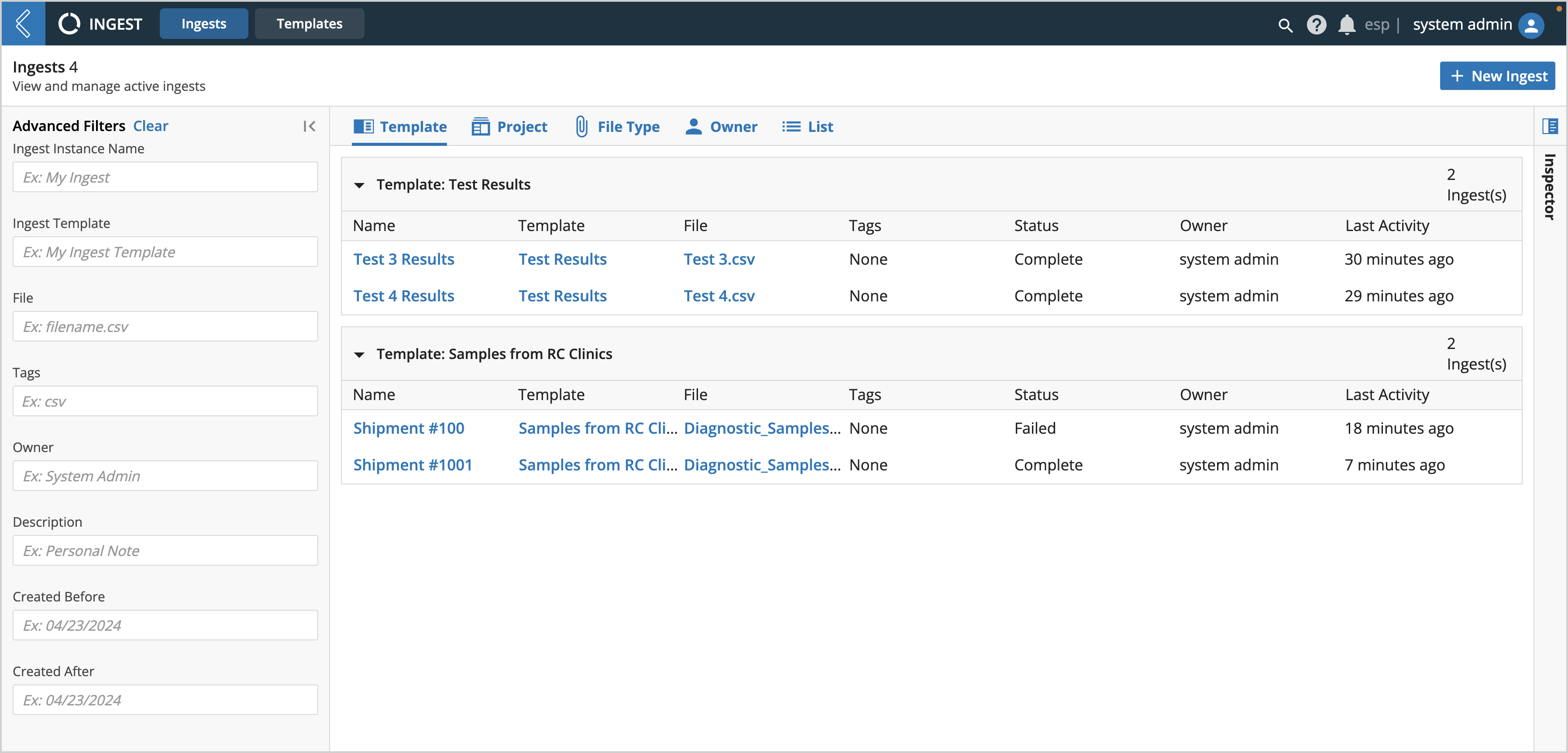 |
To view the details of an Ingest, including what the uploaded file looks like and what Entities were created, click on its Name.
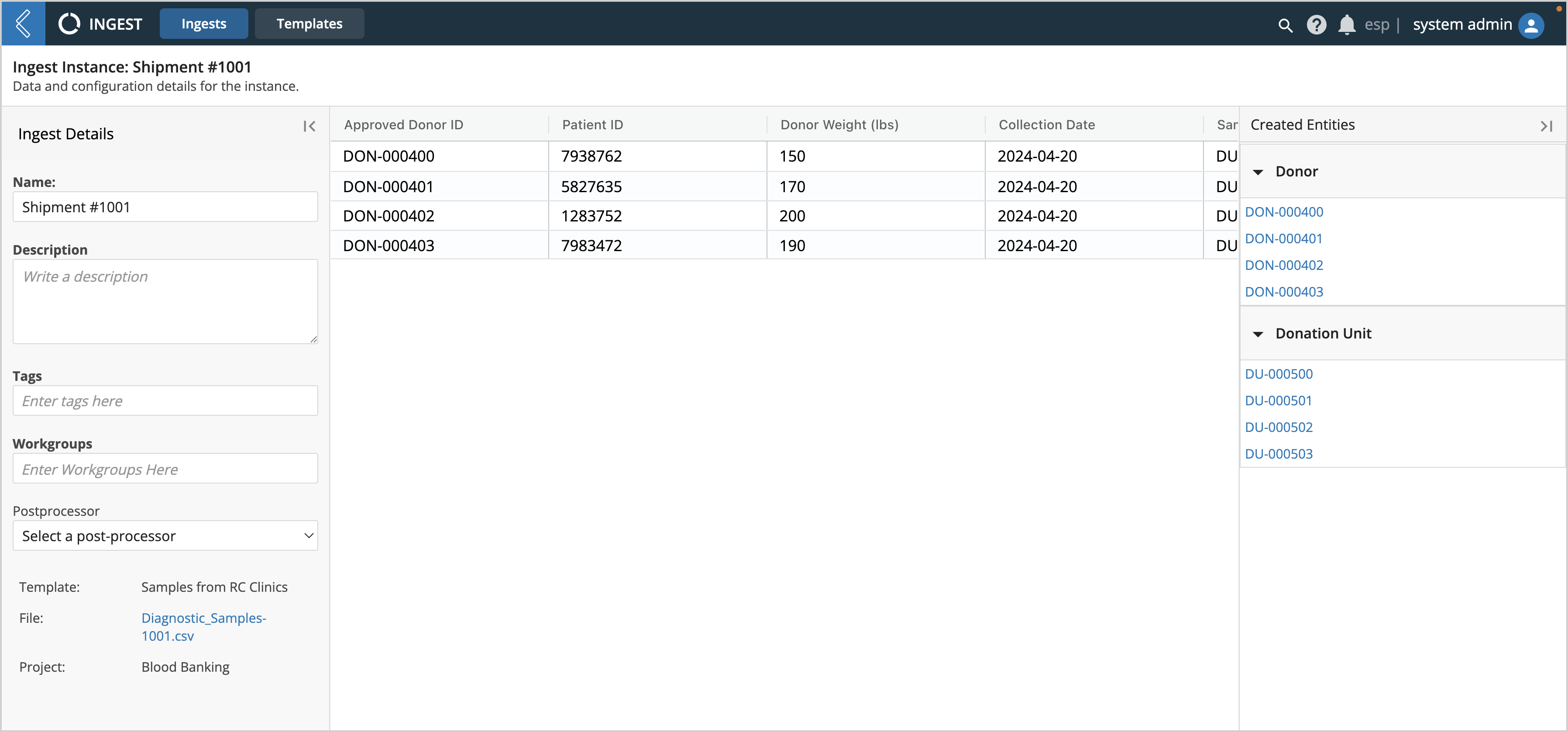 |
Steps
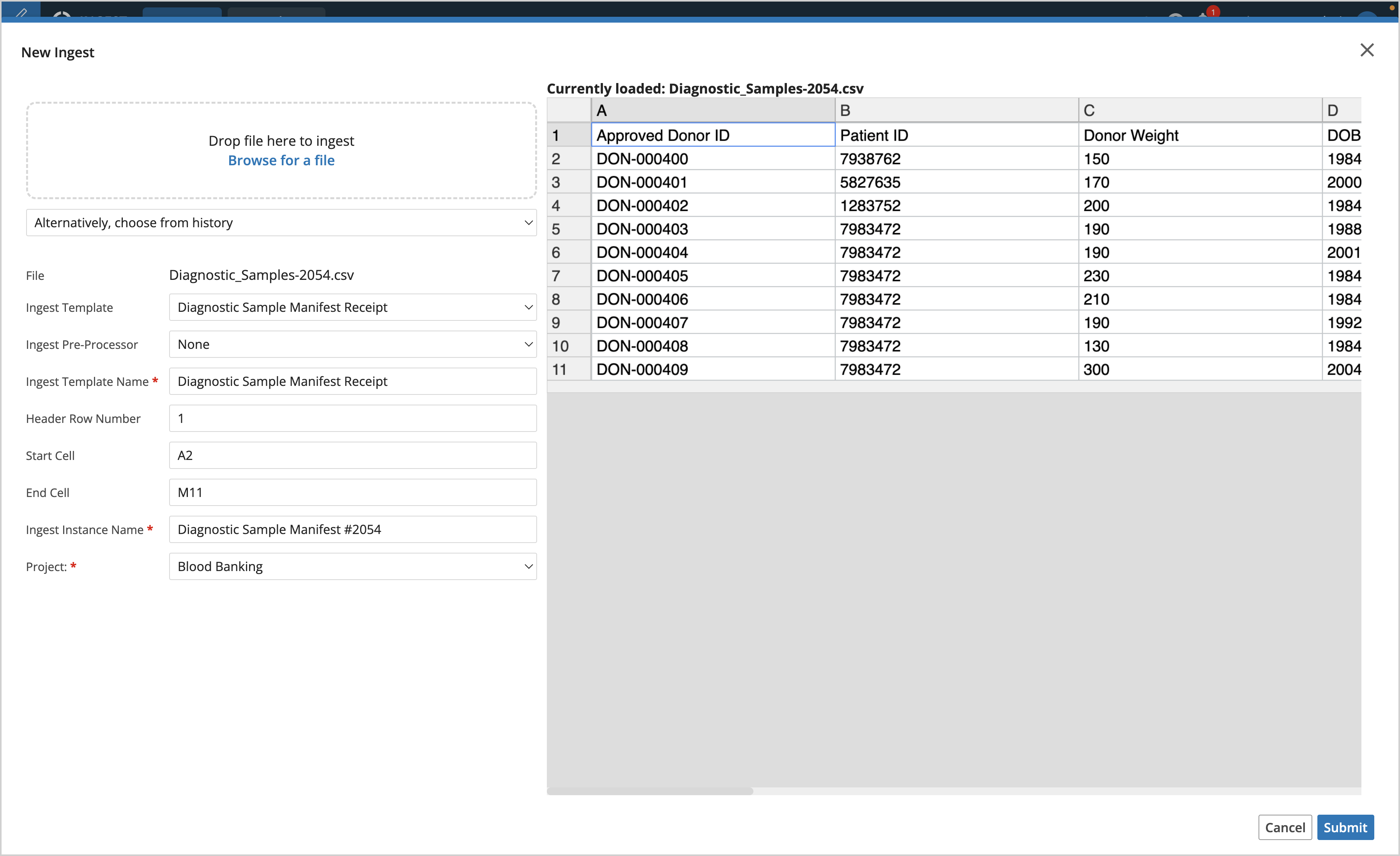
Go to: Ingest app -> Ingests -> + New Ingest
Select a file to upload
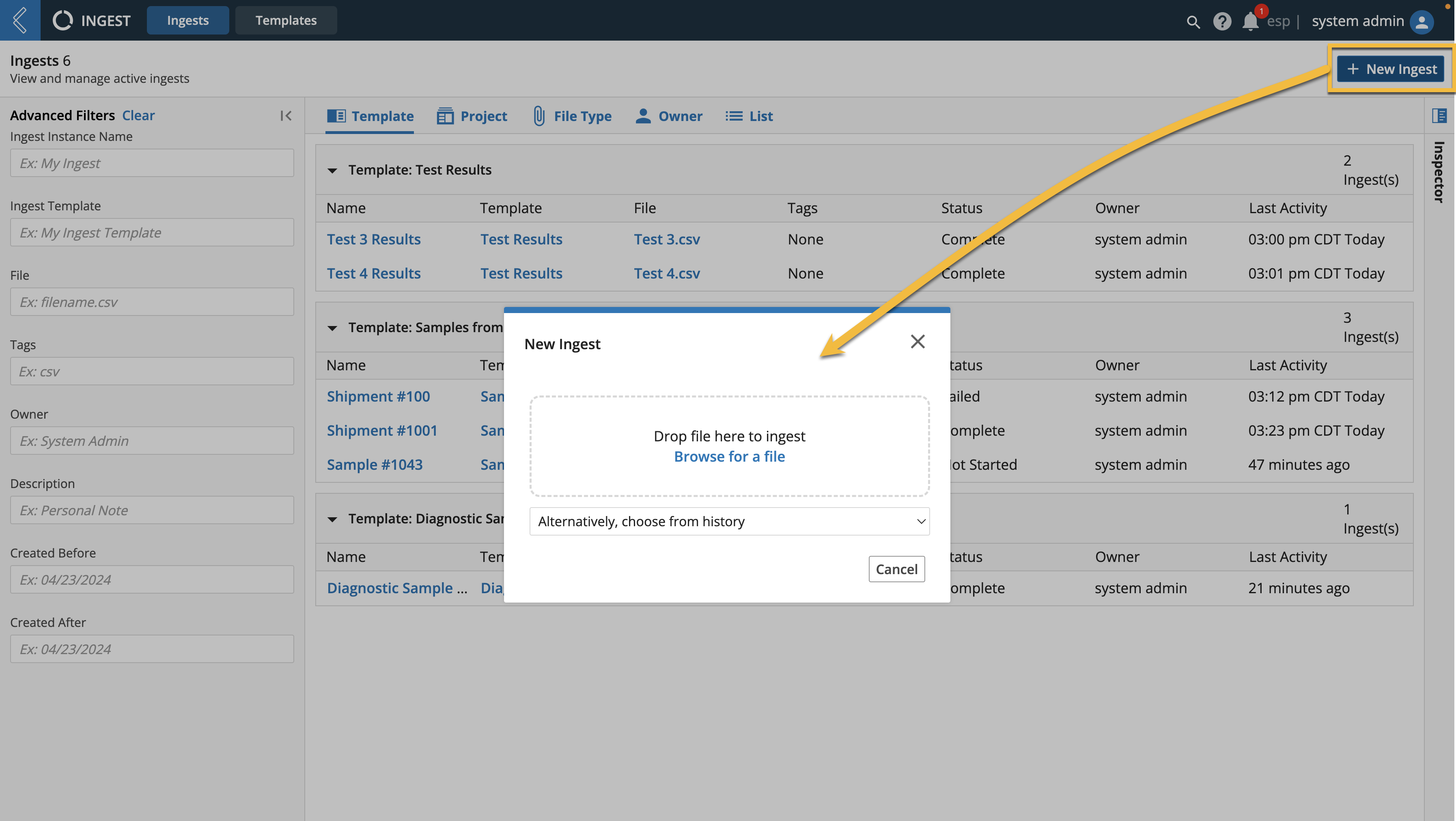
Select an existing template from the Ingest Template picklist
Select a Ingest Pre-Processor, if applicable
Enter the row number of where the header for the data occurs, Header Row Number defaults to row #1
Select the region within the file where you want to ingest data by defining the Start Cell and End Cell
Enter an Ingest Instance Name
Assign the Ingest to a Project (created in the Projects app)
Click Submit
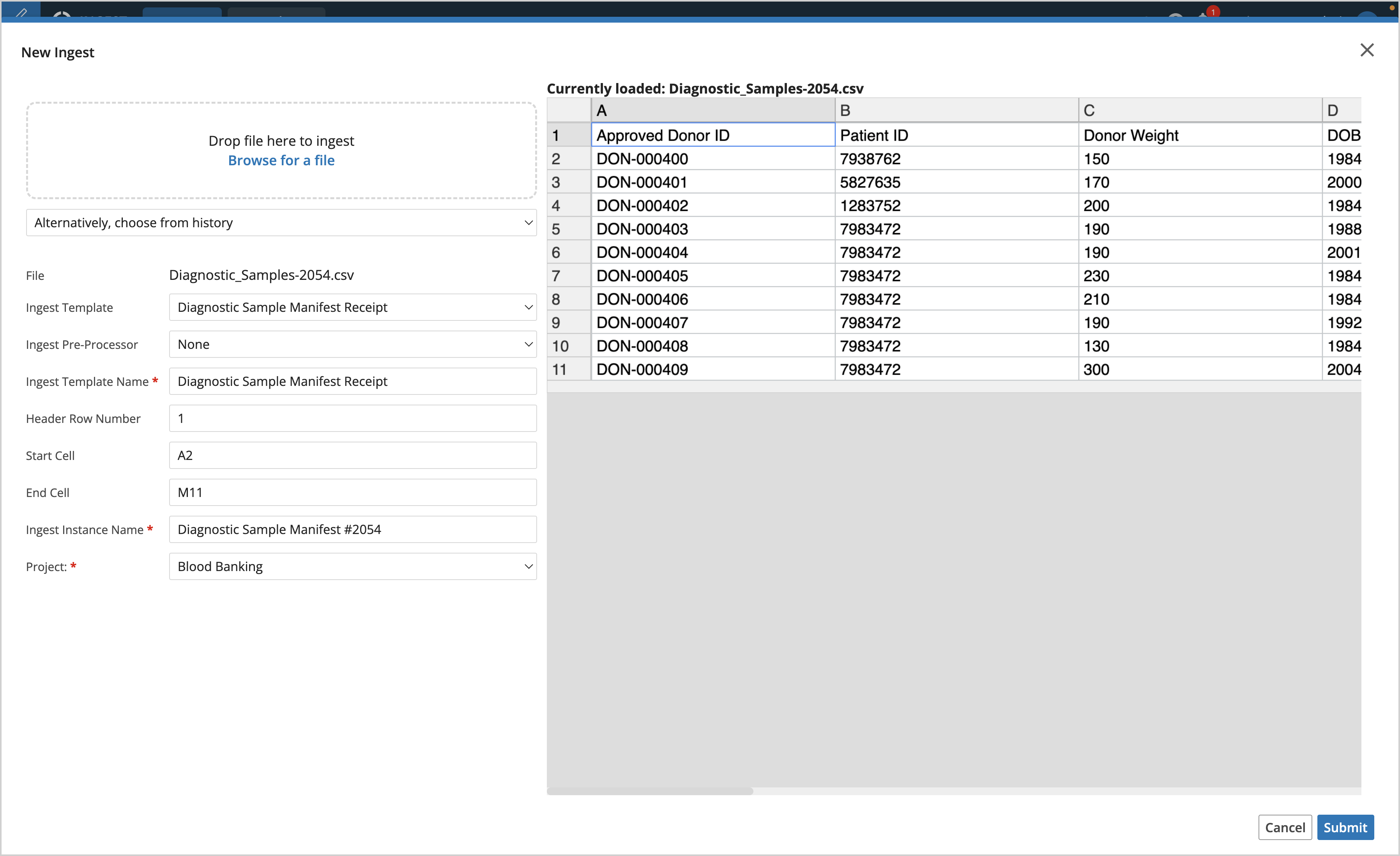
Click Process Ingest (initiates the Ingest, the action can only be performed once and can not be undone)
Note
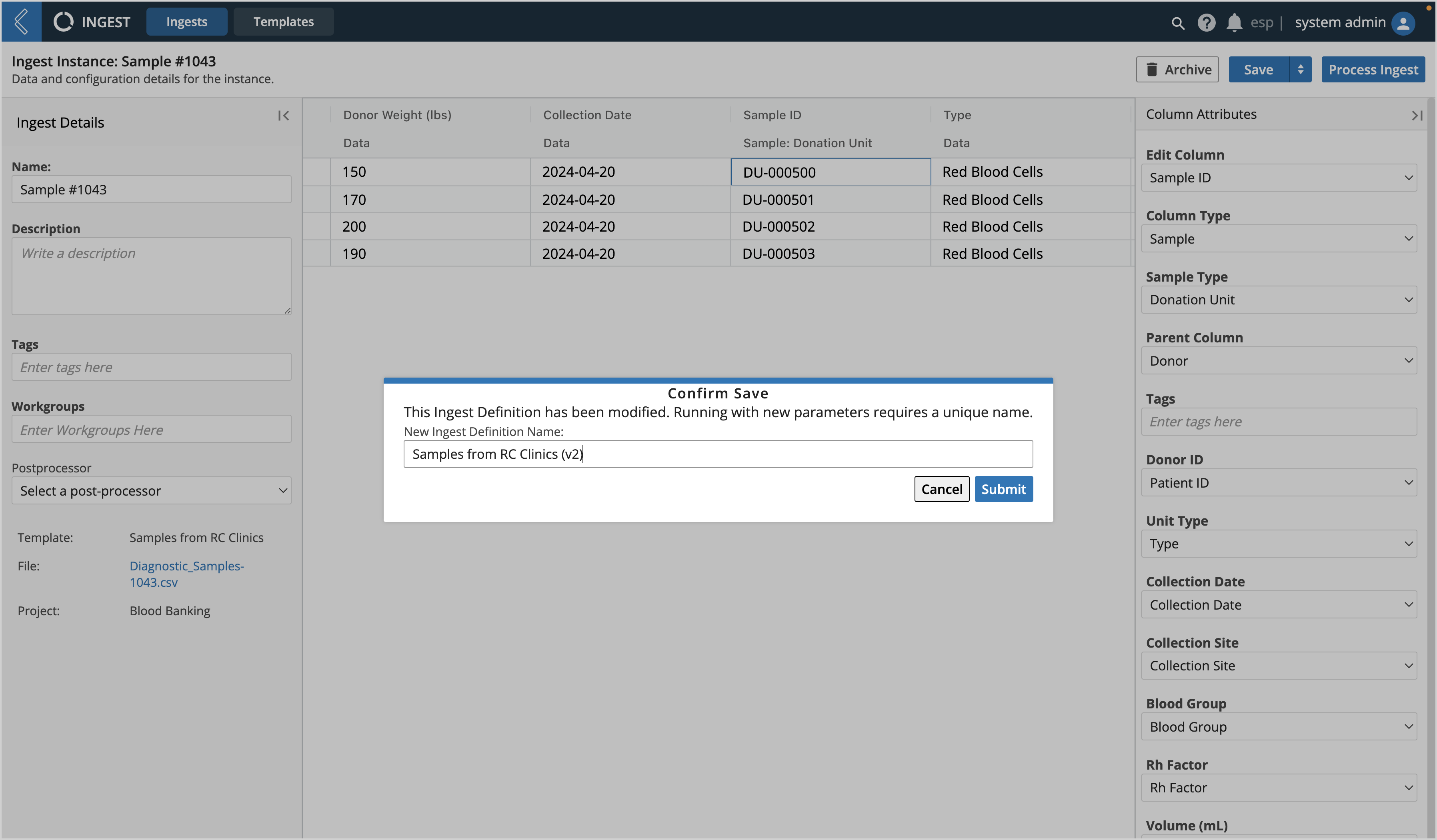
Column Attributes changes may be made before processing the Ingest, however doing so will modify the Ingest Definition and will require a new unique name.
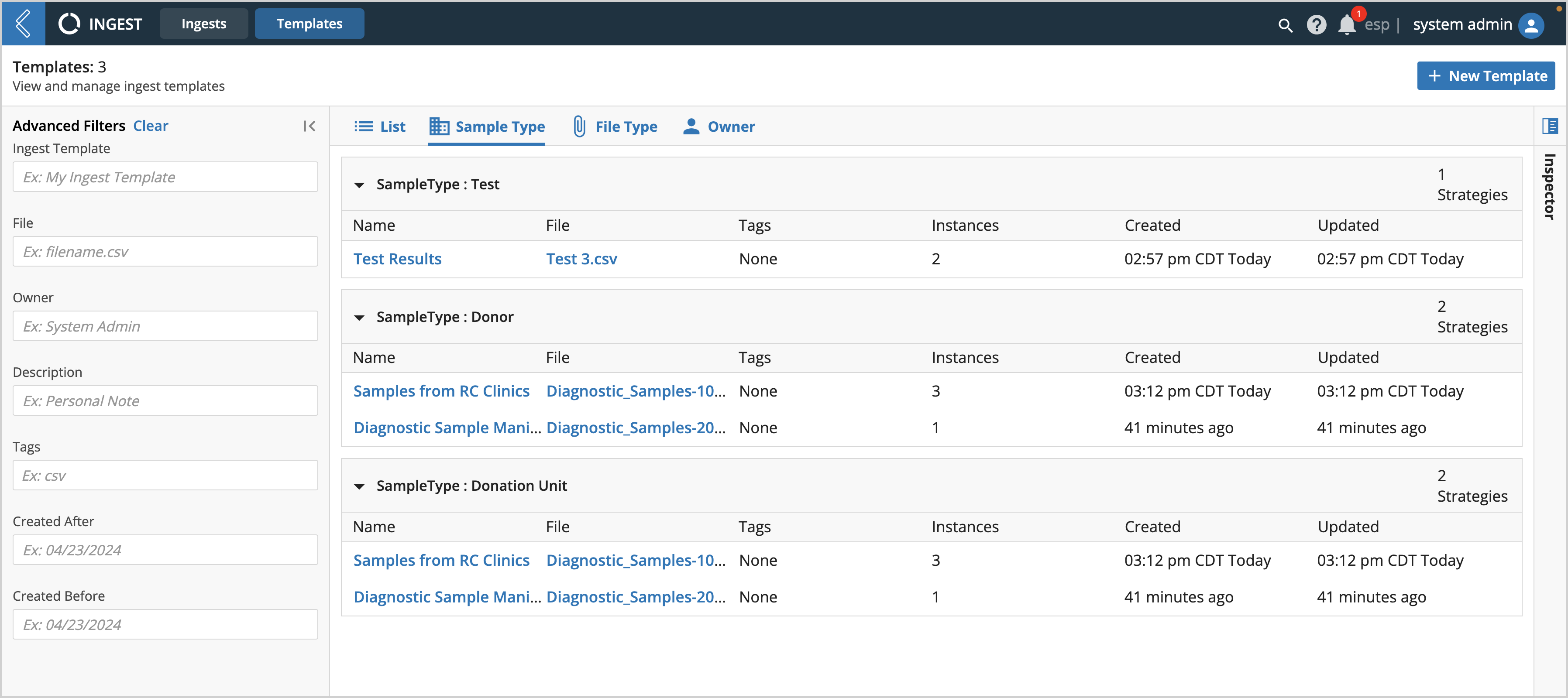
From the Templates tab you can see an overview of all active Ingest Templates, including details about the file used to make it, tags, the number of Ingest instances processed with it, and creation history. Templates can be viewed as a List or organized by the Sample Type being imported, File Type being processed, and Owner.
 |
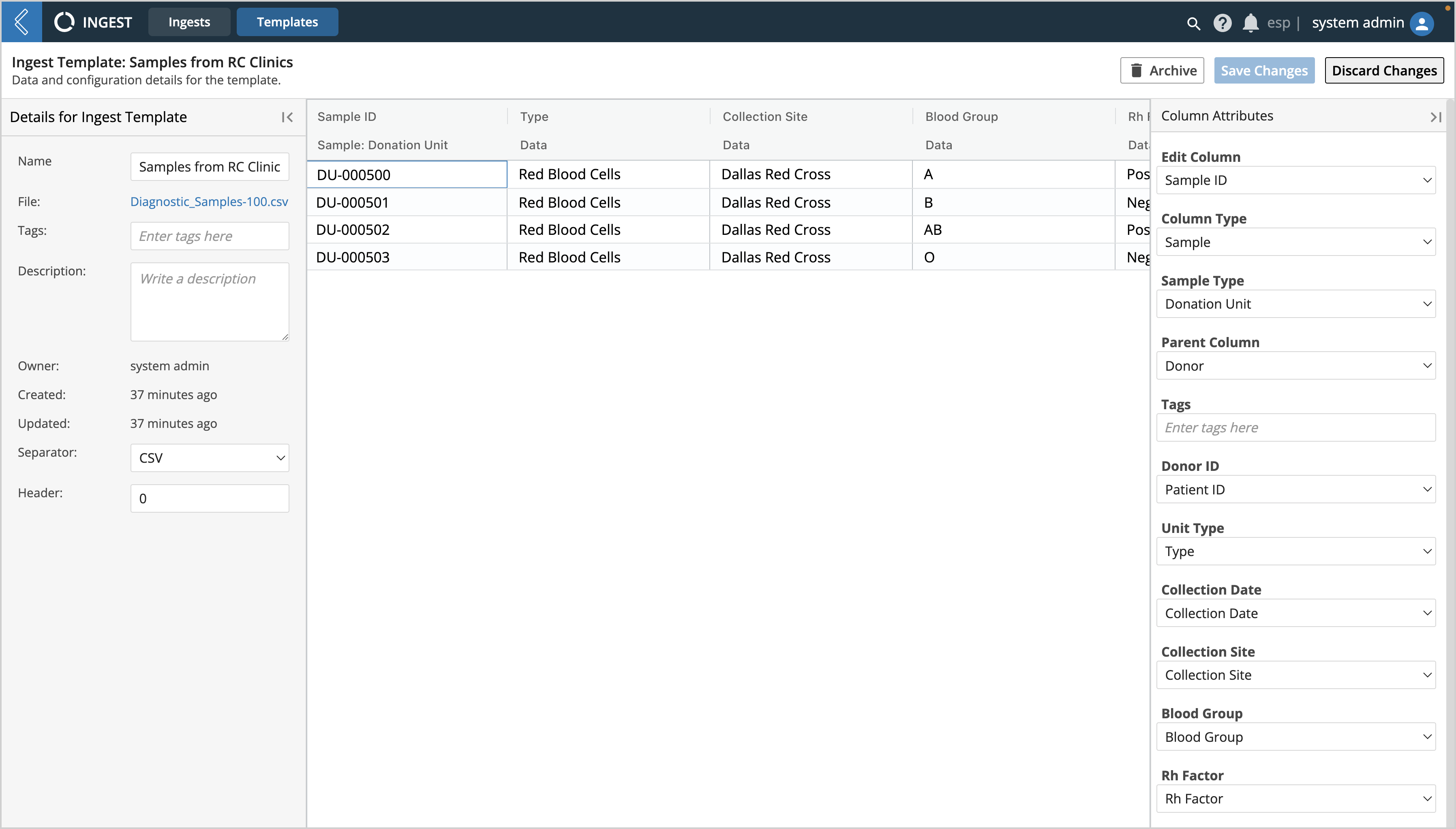
To view the details of a Template or make changes to an existing template, click on its Name.
 |
In order to evaluate and format the data, an Ingest follows the rules defined by the column rules assigned to it—whether it be by a pre-created Template from the "Templates" tab or on a unique, Ingest-by-Ingest basis through the Ingest tab.
Steps
Go to: Ingest app -> Templates tab
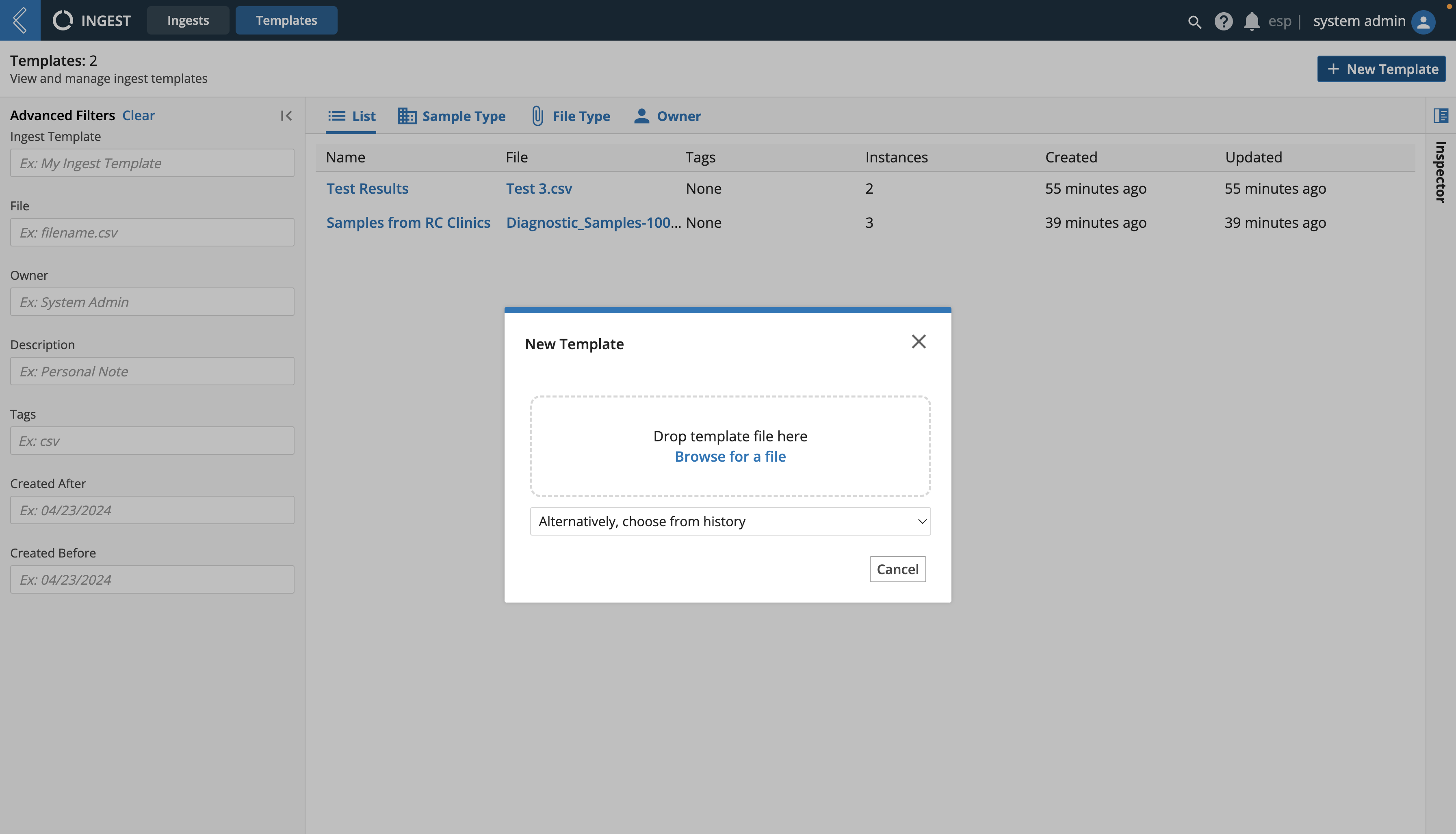
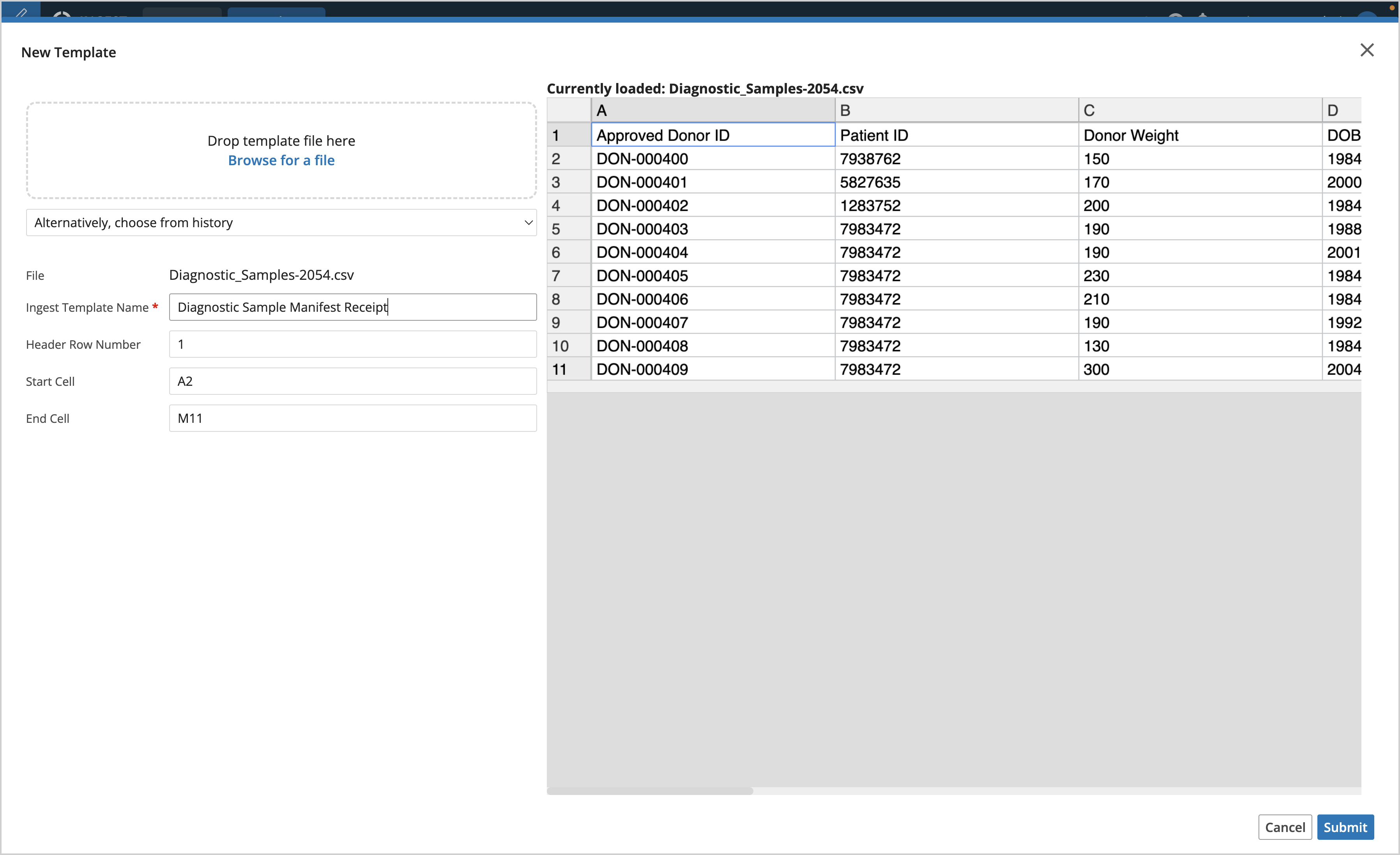
Click + New Template
Select a file to upload
Enter an Ingest Template Name
Enter the row number of where the header for the data occurs, Header Row Number defaults to row #1
Select the region within the file where you want to ingest data by defining the Start Cell and End Cell
Click Submit
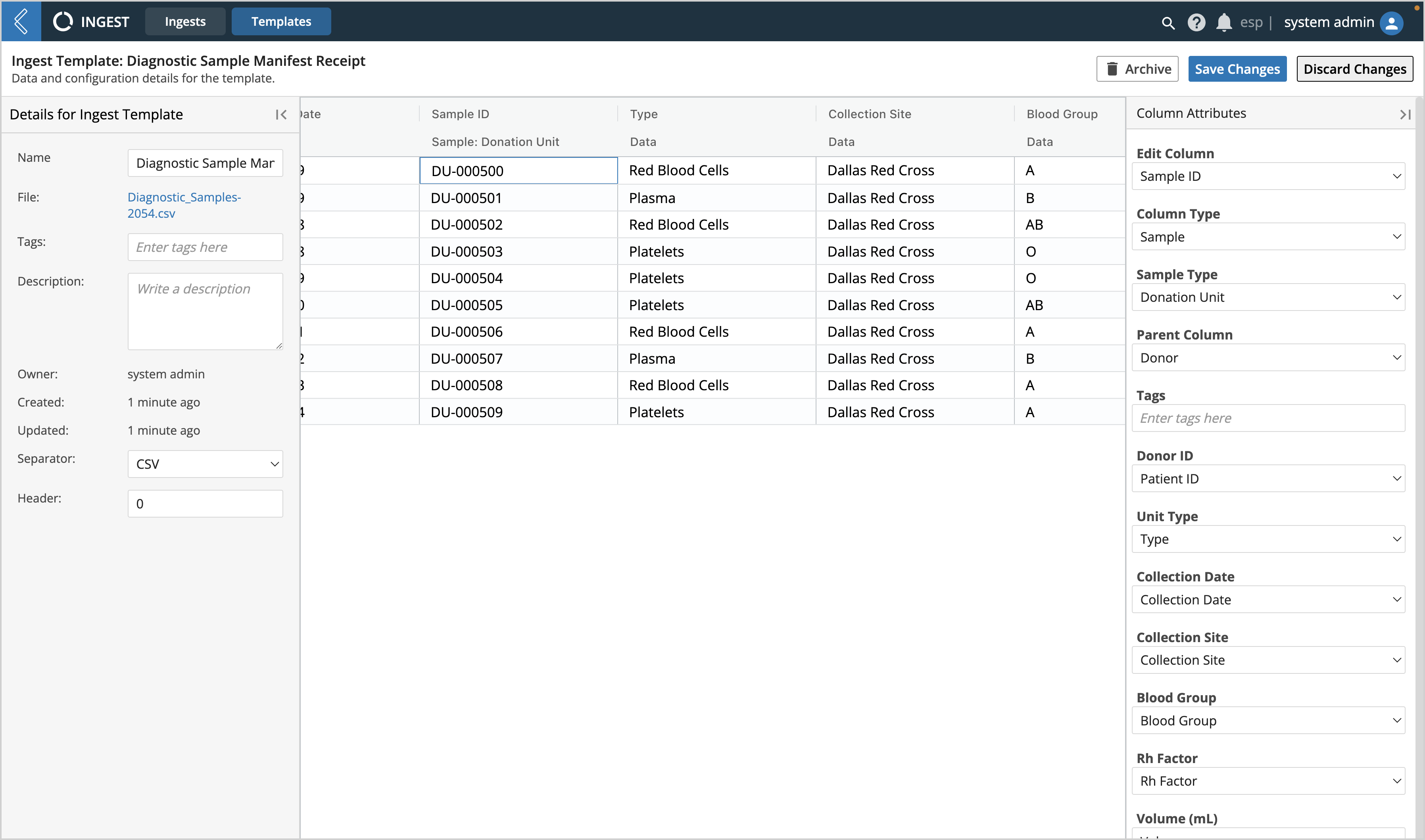
Select a cell within a column to open the Column Attributes panel
Define the Column Type for each field as either Data, Sample, or Tag; fill out accompanying Column Attribute settings as applicable
Select Save Changes when done
 |
File - select a file to upload by dropping a file, browsing for a file, or choose from history. Allowable formats to Ingest include: .txt, .tsv, .csv, .xlsx, and .json. JSON data must be structured in a format suitable for parsing into a tabular file.
Note
Date fields are required to be in ISO8601 format (i.e., %Y-%m-%d). If processing files with dates in a non-ISO-8601 format, you would write a preprocessor to convert them to ISO-8601 format. After processing, L7|ESP will automatically convert the date/time to match the format as defined by the Entity Type’s Date/Time custom field. If you are a developer, see X for an example of creating pre-processors.
Note
Ingesting the same Entity multiple times will update custom field values when changes are detected, any new tags will be appended to the Entity, and a record of every Ingest will be appended and displayed under the Process Data tab.
Ingest Template - select either an existing template, or create a New Ingest Template in the moment on an Ingest-by-Ingest basis
Ingest Pre-Processor - specifies the data format manipulation to be performed before submitting the file for ingest, L7|ESP comes with a few examples, include:
add_row_number - appends a column with rows numbered 1-N
Simple_pivot_example - example of using pivot tables to clarify the data and reduce redundancy (when previewing the file, this pre-processor will not change the appearance of the preview display)
Simple_transpose_example - example of transposing rows and columns (when previewing the file, this pre-processor will not change the appearance of the preview display)
Note
If you are a developer interested in creating your own custom processors, refer to section How Developers Can Create Processors and User Documentation section 7 Extending L7|ESP.
Ingest Template Name - name of the reusable template
Header Row Number - the row number of where the header occurs within the file
Start Cell - first position within the file of the where the relevant data to ingest is located (top left cell of the selected region)
End Cell - last position within the file of the where the relevant data to ingest is located (bottom right cell of the selected region)
Ingest Instance Name - each ingest instance, or execution, requires a unique name associated with the ingest
Project - each ingest must be associated with an existing Project made in the Projects app
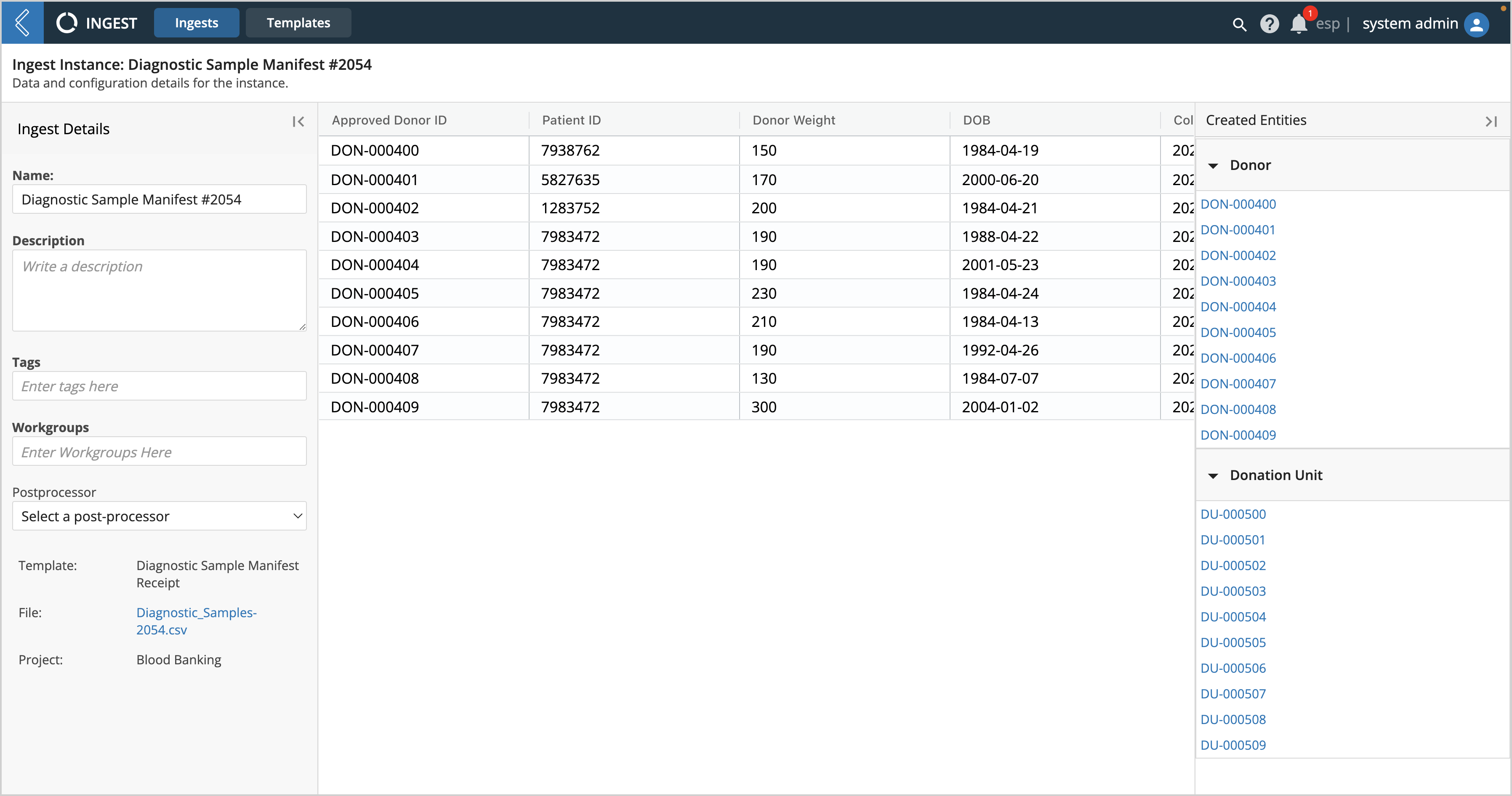 |
Name - name of the Ingest instance
Description - description of the Ingest instance
Tags - searchable text assigned to the Ingest instance
Workgroups - restricts who has access to the Ingest
Postprocessor - defines which action should be performed after performing the Ingest
Send notification - this will send an L7|ESP notification with:
Title: “Completed Ingest <ingest instance name>"
Body: "This is a demonstration of using a postprocessor", which links back to the ingest instance details
To: admin@localhost
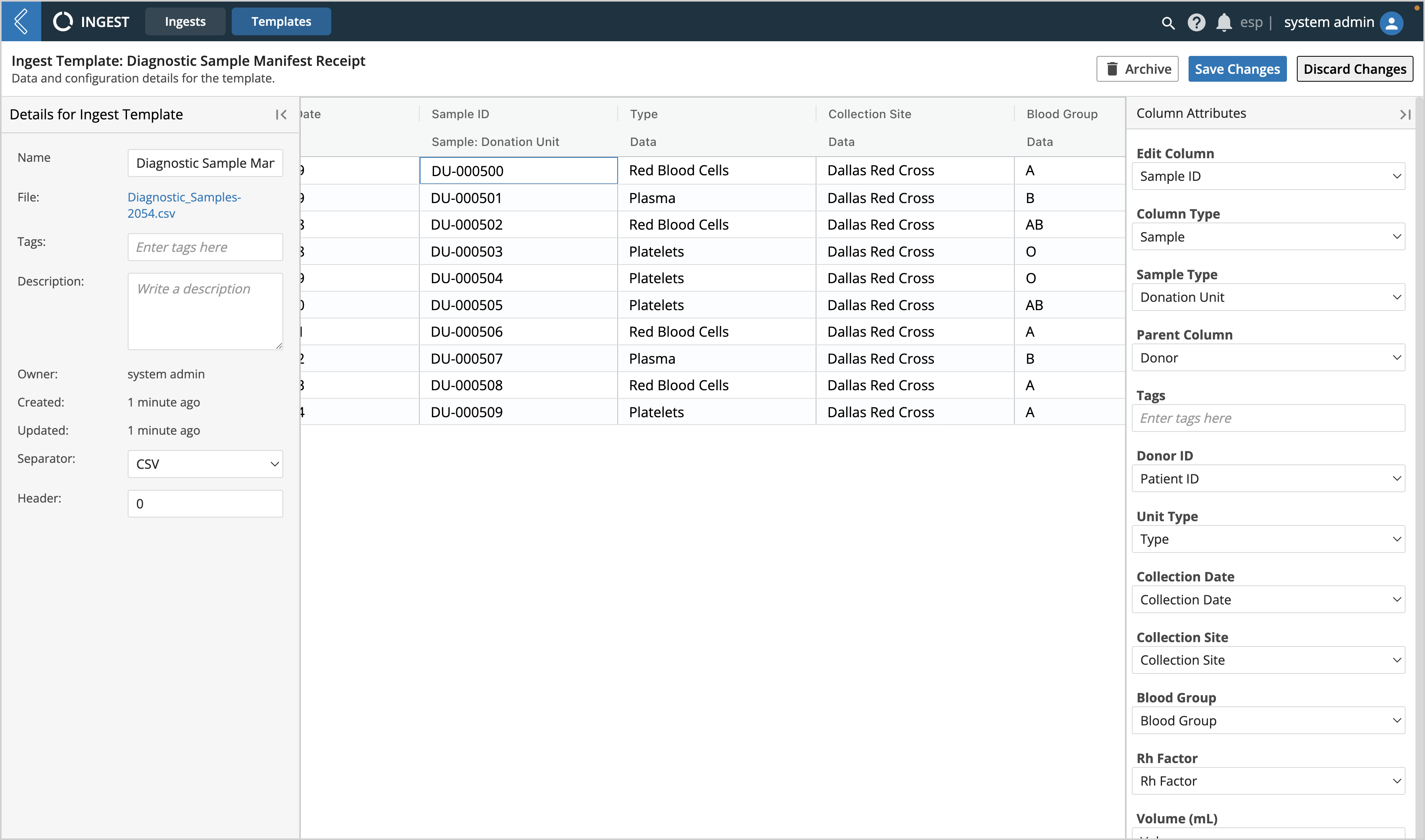 |
Edit Column - list of the column headers within the selected ingest region of the file, select the one you wish to edit
Column Type - defines how the text within the selected column should be treated
Column Type | Use Case | Additional Settings |
|---|---|---|
Data | Used to indicate the field may be assigned as metadata to a Entity |
|
Sample | Used to indicate the field is used to create a new Entity, the field should contain the Entity’s ID sequence. Multiple columns may be assigned to type “Sample” to register multiple Entity Types from one file, and establish parent-child relationships |
NoteL7|ESP will apply the text in this field as the Entity’s ID name, without enforcing the ID sequence format to adhere to the ID sequence format assigned to the Entity Type in L7|MASTER.
NoteIn the file, the parent Entity column should occur anywhere to the left of the child Entity column.
|
Tag | Used to indicate the field’s value should be appended as a dynamic tag to all newly created Entities (applies to both parents and children) |
|
Example of Creating Pre and Post Processors
L7|ESP comes with a few examples of how to create pre- and post-processors, which are code-based extensions. Upon creation, they will be auto-populated like other extensions, and will appear as picklist options for end users to select when creating Ingests in the user interface.
Below is a deeper dive into the code used to generate two preprocessor examples and their expected behaviors.
To learn more about server-side extensions, refer to the User Documentation section 7 Extending L7|ESP.
simple_pivot_example
Code
@preprocessor(name="simple_pivot_example")
def simple_pivot_example(data, parameters, context):
"""
This method is an example of how to process a file with preprocessors. In
this case we are using pivot tables to clarify the data and reduce
redundancy.
File data looks like this:
data = [['date','symbol','open','high','low','close','volume'],
['2019-03-01','AMZN','1655.13','1674.26','1651.00','1671.73','4974877'],
['2019-03-04','AMZN','1685.00','1709.43','1674.36','1696.17','6167358'],
['2019-03-05','AMZN','1702.95','1707.80','1689.01','1692.43','3681522'],
['2019-03-06','AMZN','1695.97','1697.75','1668.28','1668.95','3996001'],
['2019-03-07','AMZN','1667.37','1669.75','1620.51','1625.95','4957017'],
['2019-03-01','AAPL','174.28','175.15','172.89','174.97','25886167'],
['2019-03-04','AAPL','175.69','177.75','173.97','175.85','27436203'],
['2019-03-05','AAPL','175.94','176.00','174.54','175.53','19737419'],
['2019-03-06','AAPL','174.67','175.49','173.94','174.52','20810384'],
['2019-03-07','AAPL','173.87','174.44','172.02','172.50','24796374'],
['2019-03-01','GOOG','1124.90','1142.97','1124.75','1140.99','1450316'],
['2019-03-04','GOOG','1146.99','1158.28','1130.69','1147.80','1446047'],
['2019-03-05','GOOG','1150.06','1169.61','1146.19','1162.03','1443174'],
['2019-03-06','GOOG','1162.49','1167.57','1155.49','1157.86','1099289'],
['2019-03-07','GOOG','1155.72','1156.76','1134.91','1143.30','1166559']]
df = pd.DataFrame(data[1:], columns=data[0])
"""
import pandas as pd
# Raise error if file_obj is not found
if data is None:
raise LookupError("File lookup failed.")
if not isinstance(data, pd.DataFrame):
raise ValueError("data should be a pandas data frame `{}`".format(type(data)))
# return pivoted market data
return df.pivot(index="symbol", columns="date", values="volume")
Expected behavior
Requires columns named "symbol", "date", and "volume" and will pivot the table such that data like:
date symbol open high low close volume 0 2019-03-01 AMZN 1655.13 1674.26 1651.00 1671.73 4974877 1 2019-03-04 AMZN 1685.00 1709.43 1674.36 1696.17 6167358 2 2019-03-05 AMZN 1702.95 1707.80 1689.01 1692.43 3681522 3 2019-03-06 AMZN 1695.97 1697.75 1668.28 1668.95 3996001 4 2019-03-07 AMZN 1667.37 1669.75 1620.51 1625.95 4957017 5 2019-03-01 AAPL 174.28 175.15 172.89 174.97 25886167 6 2019-03-04 AAPL 175.69 177.75 173.97 175.85 27436203 7 2019-03-05 AAPL 175.94 176.00 174.54 175.53 19737419 8 2019-03-06 AAPL 174.67 175.49 173.94 174.52 20810384 9 2019-03-07 AAPL 173.87 174.44 172.02 172.50 24796374 10 2019-03-01 GOOG 1124.90 1142.97 1124.75 1140.99 1450316 11 2019-03-04 GOOG 1146.99 1158.28 1130.69 1147.80 1446047 12 2019-03-05 GOOG 1150.06 1169.61 1146.19 1162.03 1443174 13 2019-03-06 GOOG 1162.49 1167.57 1155.49 1157.86 1099289 14 2019-03-07 GOOG 1155.72 1156.76 1134.91 1143.30 1166559
Becomes:
date 2019-03-01 2019-03-04 2019-03-05 2019-03-06 2019-03-07 symbol AAPL 25886167 27436203 19737419 20810384 24796374 AMZN 4974877 6167358 3681522 3996001 4957017 GOOG 1450316 1446047 1443174 1099289 1166559
simple_transpose_example
Code
@preprocessor(name="simple_transpose_example")
def simple_transpose_example(data, parameters, context):
"""
Example preprocess method. Takes file object from decorator and returns a
two-dimensional array of data.
File data looks like this:
[
['Trilogy', 'First Entry', 'Second Entry', 'Third Entry'],
['Prequel', 'The Phantom Menace', 'Attack of the Clones', 'Revenge of the Sith'],
['Original', 'A New Hope', 'The Empire Strikes Back', 'Return of the Jedi'],
['Sequel', 'The Force Awakens', 'The Last Jedi', 'The Rise of Skywalker']
]
"""
import pandas as pd
# Raise error if file_obj is not found
if data is None:
raise LookupError("File lookup failed.")
if not isinstance(data, pd.DataFrame):
raise ValueError("data should be a pandas data frame `{}`".format(type(data)))
# Create a transposed version of file data and return it.
return df.set_index("Trilogy").TExpected behavior
Requires a column named "Trilogy" and will transpose the table based on the value of that column. For instance:
Trilogy First Entry Second Entry Third Entry 0 Prequel The Phantom Menace Attack of the Clones Revenge of the Sith 1 Original A New Hope The Empire Strikes Back Return of the Jedi 2 Sequel The Force Awakens The Last Jedi The Rise of Skywalker
Becomes:
Trilogy Prequel Original Sequel First Entry The Phantom Menace A New Hope The Force Awakens Second Entry Attack of the Clones The Empire Strikes Back The Last Jedi Third Entry Revenge of the Sith Return of the Jedi The Rise of Skywalker