Backup and Disaster Recovery
Introduction
This document outlines strategies for backup, recovery and DR, as it pertains to the ESP server application. These suggestions can be implemented to achieve highly available (HA) infrastructure as well as help inform decisions when performing risk analysis related to your own internal business continuity (BC) guidelines and policies.
Risk Analysis
Determining the correct level of redundancy, HA, and backups should be defined by internal IT/DevOps/Business policies and processes to determine RTO (Recovery Time Objective) and RPO (Recovery Point Objective) values to meet any organizational defined SLO (Service Level Objective). One possible decision factor is the cost of implementing redundancy or HA versus lost revenue, reputation, and internal staff time associated with downtime.
Backup
Recommendations and examples
For atomic/PITR (Point in Time Recovery) backups, we recommend always backing up the database first, followed by the shared data volume (/opt/l7esp/data). This will ensure that all files referenced by the database backup are included in the whole backup.
At minimum L7 recommends whether performing a “hot” or “cold” backup:
Keep copies of each deployment bundle that you deploy, since these contain information about the version of the software, as well as the configuration that was applied.
Using
pg_dump --format="c"for PostgreSQL database backups so you may be able to restore the backups with thepg_restorecommand. If you prefer to create backups in a different format with thepg_dumpcommand, note that you will likely have to pipe the backup file into thepsqlPostgreSQL command-line utility to perform a restore.If the data volume exists outside of the default location (e.g. NFS/EFS mount) this should be backed up as well.
Backup the deployed installation tarball to be able to reinstall if required.
One example of a backup strategy is to first backup the database to the shared data volume, then perform a backup of the data volume which will always result in atomic backups.
An option for AWS provisioned environments is the use of a managed service such as AWS Backup, which offers the following features:
Centralized backup management
Policy-based backup solution
Tag-based backup policies
Automated backup scheduling
Automated retention management
Backup activity monitoring
Lifecycle management policies
Incremental backups
Backup data encryption
Backup access policies
Amazon EC2 instance backups
Item-level recovery for Amazon EFS
Cross-region backup
Cross-account backup
One thing to keep in mind when utilizing a managed service to perform a “hot backup” is that any RDS backup occurs before any EBS/EFS/NFS volumes to provide a valid restore point.
It is also highly recommended to regularly audit and test your backup/restore strategy to ensure it can be performed successfully as well as complies with any organizational policies and regulatory controls.
Common disaster-recovery instance requirements
The disaster-recovery installation must have the same product version and patch level as the production installation.
If any configuration or file changes (such as applying patches) are made to the production instance, the same changes must be repeated on the disaster-recovery instance.
As the production system is used, all data changes must be replicated to the disaster-recovery instance. These changes can be database changes or file system changes, depending on the product in use.
Replicating data changes imposes additional demands on the resources in the production system. To keep these demands to a minimum, the replication schedule should be carefully considered. If continuous replication is needed, the production system must be given additional resources (CPU and memory) to reduce the performance impact.
Disaster Recovery
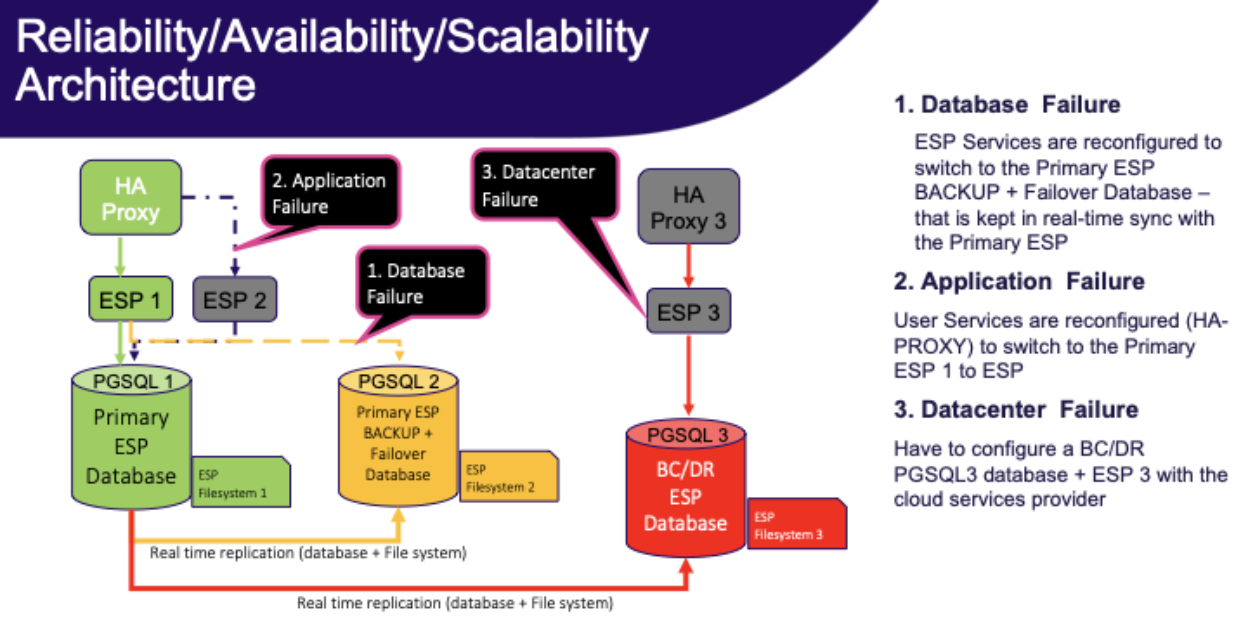
Definitions
Hot standby is a server that will automatically failover if the primary server fails.
Warm standby is a server that will not automatically failover and that may not have all the latest transactions.
Cold standby is a spare machine that needs to be turned on, backup restored (or even full staging of the machine).
Scenarios
Application failure
In the event of an ESP application server failure:
Hot standby: Two ESP application servers behind a load balancer.
Note
User-uploaded files and pipeline scripts/log files that are referenced by the database are written as physical files to disk and are not stored inside the database as blobs for a number of reasons, such as performance. You should take care to mount these directories to a networked storage solution, such as an AWS EFS filesystem.
Warm standby: Alternatively, you may cut traffic to another ESP application server of the same version, and sync the files in the ESP data volume using an out-of-band process, such as scheduled rsync. Using physical disks vs networked storage will increase file system performance and may reduce cost, but the file synchronization process will likely be eventually-consistent in nature.
Cold standby: For this scenario, in the event of a failure, you can quickly bootstrap a new ESP application server either by installing a tarball on a fresh Linux server. Alternatively, if you create an image (e.g. AWS AMI) for an installed server, you can create a new VM from this image or even automate the process by using an AWS ASG with the correct policy and health checks.
Database failure
In the event of a PostgreSQL database server failure:
Hot standby: The main use case for a hot standby is load balancing. You would use this to reduce to load on the database master server by delegating requests to one of more standby servers. To configure this, you must increase wal_level to hot_standby on the master database server and set hot_standby to on at the standby database servers. At a high level, most “clustered” PostgreSQL configurations can be considered hot standby, such as using more modern streaming replication modes.
Warm standby: You can transfer a PITR backup to a standby database server and set it to always run an endless recovery process using WAL logs from the master database server. In this configuration, the standby database server is not accepting queries and sharing the load, but can be made available in the event of a failure. To configure this, you must specify wal_level=replica; archive_mode=on on the master database server and set standby_mode to on at the standby database server(s). When using a hosted service such as AWS RDS, you can simply enable the “Multi-AZ deployment” option when provisioning your database server.
Cold standby: In this failure scenario, you would be configuring a new database server and restoring from backup. In AWS RDS, this would be equivalent to restoring a database instance from a snapshot.
Datacenter failure
In the event of a catastrophic datacenter (or regional, in cloud terms) failure:
Hot standby: To achieve this scenario, you must have duplicate infrastructure running in another datacenter or region, with database and file synchronization between these sites. There is a cost vs risk tradeoff to be made as this can cost up to double the price, whereas the likelihood of this event may not mandate automated failover at this level.
Warm standby: This is the same as a hot standby from a cost perspective as you would have duplicate infrastructure running, however you are failing over to the standby site by manually altering DNS records in the event of a failure.
Cold standby: In this failure scenario, you would have a spare machine or the ability to provision one, in another network. The ESP application would need to be installed and backups restored to make it functional, and DNS updated to direct traffic here afterwards. In AWS, you could spin up a copy of the ESP infrastructure in another region using existing IaC in the unlikely event that this scenario ever occurs.